
통계작업을 위해 데이터를 샘플링하는 경우가 있습니다.이때 Sybase IQ에서는 RAND() 함수를 사용하면 쉽게 샘플링 데이터를 얻을 수 있습니다.ex) 2012년 1월 거래 데이터에서 5% 데이터를 샘플링하기SELECT *FROM 거래WHERE 년월 = '201201' AND RAND(ROWID(거래)) < .05;정해진 건수 예를 들어 10만건 이렇게 구해야 한다면 먼저 적당한 %를 구한 다음에 TOP으로 가져오면 되겠죠. PS) 오라클을 사용한다면 아래와 같이 하면 됩니다.SELECT *FROM 거래 SAMPLE(5)WHERE 년월 = '201201' ;또 다른 방법SELECT *FROM (SELECT * FROM 거래 WHERE 년월 = '201201' ORDER BY DBMS_RANDOM.VA..
ESQLC에서 데이터를 Array Fetch한 후 변경된 정보르르 다시 업데이트 하고자 할때 PRO*C처럼 안되더군요. PRO*C에서는 Array Fetch한 것을 다시 Array로 업데이트 할 수 있는데 ESQLC에서는 방법을 찾질 못했습니다. 그래서 찾아낸 최적의 방법이 Fetch한 결과를 가공한 뒤 파일로 저장하고, 이것을 Temp 테이블에 로드한 후 JOIN 업데이트를 하는 방법 이었습니다. 혹시나 PRO*C 처럼 구현할 수 있는 방법을 알고 계신분은 댓글을 달아 주십시오. ^^
Embeded SQL로 오라클에서는 PRO*C를 Sybase를 비롯 여러 업체는 ESQLC를 사용합니다. 요즘 ESQLC를 하면서 PRO*C와 다른점이 있어서 포스팅 합니다. 부득이하게 클라이언트로 결과를 Fetch하는 경우에 성능 향상을 위해 Array Host 변수를 사용하죠. 즉 한번 Fetch 명령으로 Array 크기만큼 데이터가 전송되도록 함을로써 Fetch 횟수를 줄여 성능 향상을 이루는 방법입니다. Fetch 할 데이터가 1500건이고 Array 사이즈가 1000 일경우 PRO*C의 경우 2번째 Fetch시 No Data Found 코드가 떨어지는 데 이때 500건의 데이터가 추가로 Fetch되었을 경우과 데이터가 없을 경우를 나눠서 처리를 해줘야 합니다. 즉 No Data Found 여도 ..
 [책 추천] 데이터 모델링 실무사례 - 최용락
[책 추천] 데이터 모델링 실무사례 - 최용락
데이터베이스 모델링에 관한 책 중에서 실무에 바로 적용하기에 가장 좋은 책인것 같습니다. 가장 기본적인 공통코드 설계 방법부터 저의 이목을 확 끌더군요. 저자가 2003년인가 출판한 "전문가를 위한 모델링 실무" 란책 있는데 내용이 거의 같습니다. 예전 책이 있으신 분들은 새로운 내용이 거의 없음으로 보지 않으셔도 될 듯 합니다. 요즘 모델링이 잘 설계 되어야 프로그래머가 편하다는 진리를 느끼며 다시 모델링 공부에 매진하고 있습니다. ^^ [목차] 제1장 데이터베이스 설계 개요 1 데이터베이스, 데이터베이스 관리 시스템, 데이터 모델 2 데이터베이스 관리 3 데이터 모델링 개념 제2장 논리 데이터 모델링 1 개체 파악 2 식별자 파악 3 상사화 4 통합 5 검증 6 사례 연구 제3장 물리 데이터 모델링 ..
 [Sybase IQ] 빅데이터 분석/처리가 가능한 15.4
[Sybase IQ] 빅데이터 분석/처리가 가능한 15.4
Sybase IQ도 드디어 빅데이터 처리가 가능하도록 진일보 했다고 합니다. 분산 처리를 위해 하둡을 지원하고, 오픈 소스 통계프로그램인 'R'을 지원하면서 데이터 마이닝을 비롯한 각종 통계 작업이 더욱 쉬워질것 같습니다. 저는 하둡은 아직 적용해 보진 않았지만 Sybase IQ + Weka를 적용하고 있는데 역시 빅 데이터 분석 시대가 대세 인듯 합니다. [기사 URL] http://www.bloter.net/archives/86742
오라클의 pro*c와 같은게 Sybase에선 ESQLC라고 있습니다. 확장자가 .pc가 아니라 .cp 죠. 문법이 pro*c와 많이 닮아 있습니다. 이게 표준이 있는 건가 (?) 아무튼 성능 향상을 위해 DBMS Call 1번에 다중 row를 select 할 수 있도록 Pro*c에서도 Array Fetch 기능을 제공하는데요. 마찬가지로 ESQLC에서도 지원합니다. 주의 할 점이 한가지 있는데요. host 변수의 크기가 조회 하려고 하는 컬럼 크기보다 작게 선언되었을 경우에 1row만 fetch되고 Array Fetch 가 되지 않는 현상이 있습니다. 실제로 host변수 크기만큼만 데이터가 들어 있어도 말이죠. 강제로 substr로 select시에 컬럼의 크기를 줄여 주거나 host변수의 크기를 늘려주면..
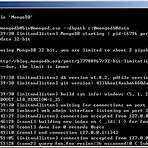
오늘 문서 작업도중 alter 문을 DML로 잘못 표기 했다. 오랜만에 DML, DCL, DDL 용어를 사용하려니 햇갈렸나 보다. 생각난 김에 다시 정리해 본다. 1. DDL(Data Definition Language) 데이터와 그 구조를 정의합니다. 1) CREATE : 데이터베이스 객체를 생성합니다. 2) DROP : 대이터베이스 객체를 삭제합니다. 3) ALTER : 기존에 존재하는 데이터베이스 객체를 다시 정의하는 역할을 합니다. 4) RENAME : 데이터베이스의 컬럼명을 변경합니다. 5) TRUNCATE : 테이블을 최초 생성된 초기상태로 만들며, ROLLBACK이 불가능합니다. 2. DML(Data Manipulation Language) 데이터의 검색, 수정, 삭제 등을 처리합니다. 1)..
- Total
- Today
- Yesterday
- 솔리드 쿨론
- 톡토기
- 별잉 빛나는 밤
- 오미크론
- 유가바이트디비
- 매직 트랙패드2
- 브리다 정수기
- Pixel Pals
- 코라나 19
- 파나소닉 비데 DL-EH10KWS
- 홈 오피스
- VARIDESK
- 카카오 에드
- Sybase IQ
- 배당급
- yugabyteDB
- 로니카 BCS
- 남설 팔찌
- 화분벌레
- 르세라핌
- node.js
- GKRS
- 빈센트 반 고흐
- 고체 향수
- weka
- 루미큐브 종류
- Life Chair
- JMW 헤어드라이기기
- 별이 빚나는 밤
- 증권정보포털
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |